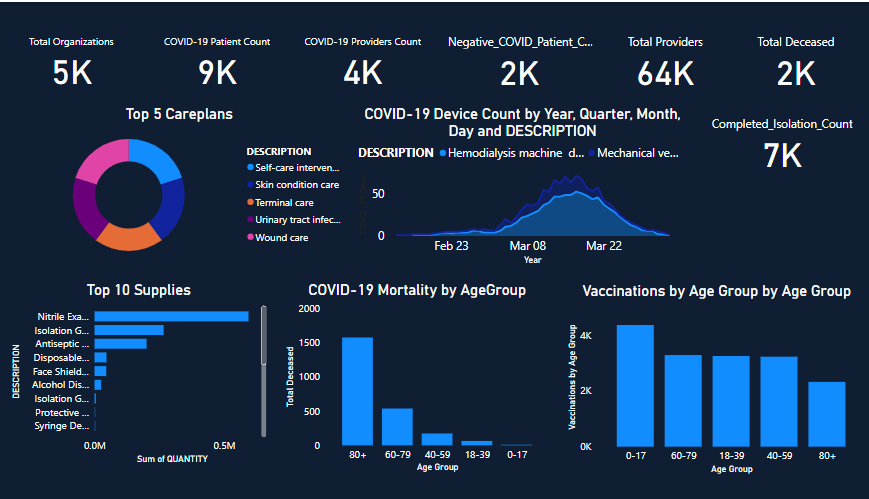
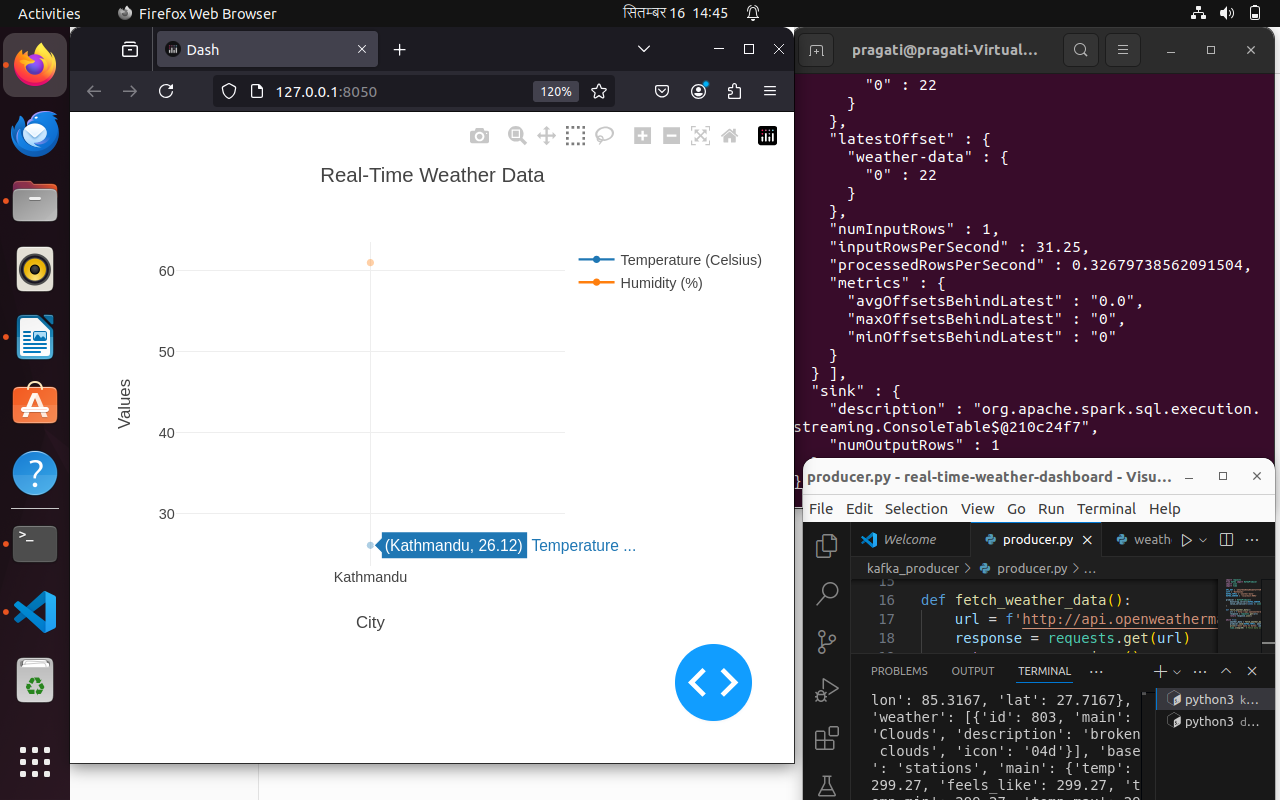
I'm a recent Computer Science graduate and entry-level Data Engineer based in Lalitpur, Nepal. I specialize in building robust, scalable ETL/ELT pipelines that move raw data from source to analytics-ready environments.
My hands-on work spans the modern data stack — from ingesting data from AWS S3 into Snowflake via bulk COPY INTO, to orchestrating complex workflows in Apache Airflow, to processing live event streams with PySpark and Kafka.
Proficient in Apache Spark (PySpark), Airflow, Kafka, and Snowflake — with experience in dimensional modeling, SCD Type 2, and Medallion Architecture (Bronze / Silver / Gold layers).
I care deeply about data quality and pipeline reliability. I containerize everything with Docker, version-control rigorously with Git, and design systems that are both maintainable and scalable. Currently seeking opportunities to grow on a team that values clean architecture and thoughtful engineering.